
CONTENTS
ChatGPTとは?
まず、ChatGPTとは何か?について、せっかくなのでChatGPTに「ChatGPTとは何ですか?」と質問してみました。すると以下のような回答がありました。
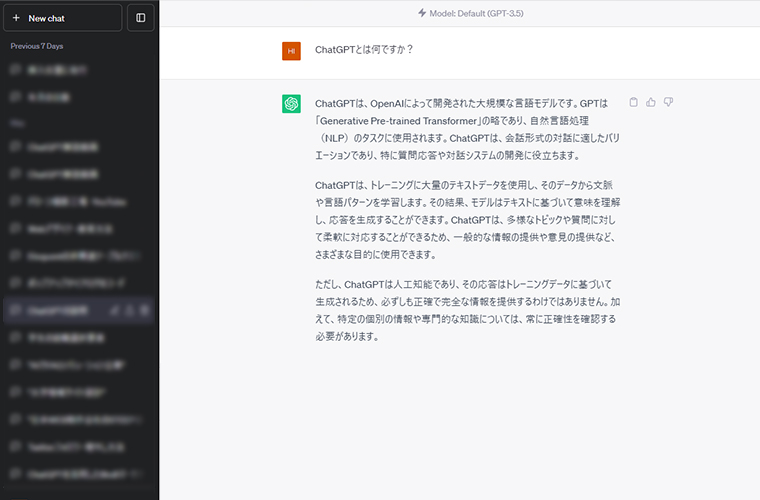
ChatGPTは、OpenAIによって開発された大規模な言語モデルです。GPTは「Generative Pre-trained Transformer」(ジェネレーティブ プリトレインド トランスフォーマー)の略であり、自然言語処理(NLP)のタスクに使用されます。ChatGPTは、会話形式の対話に適したバリエーションであり、特に質問応答や対話システムの開発に役立ちます。ChatGPTは、トレーニングに大量のテキストデータを使用し、そのデータから文脈や言語パターンを学習します。その結果、モデルはテキストに基づいて意味を理解し、応答を生成することができます。ChatGPTは、多様なトピックや質問に対して柔軟に対応することができるため、一般的な情報の提供や意見の提供など、さまざまな目的に使用できます。
ChatGPTより引用
このようなシンプルな質問でも、かなり正確かつ大量の情報を返してくれます。次に、どういう仕組みになっているのかの、中身について触れていきます。
GPTとは?
ChatGPTの「GPT」とは何か一言でいうとAIの「モデル」の一つで、「モデル」とは、AIの脳みそ部分を表す言葉です。質問をモデルに入力すると回答を出力するという図式になっていて、先ほどの質問を例にすると「ChatGPTとは何ですか?」という入力に対して考えて答えを出し、出力するという一番コアな部分をモデルといいます。
GPTの特徴
GPTには、2017年にGoogleから発表された「Transformer」というモデルが採用されています。この「Transformer」というモデルに、大量のテキスト情報(Wikipediaなど)を事前学習という手法で学習させて成り立っているものがGPTになります。
GPTの進化
現在GPTの最新バージョンはGPT-4です。(2023年5月時点)GPT-4にいたるまでどのように進化を遂げてきたかをご紹介いたします。2018年にGPT-1というモデルが発表され、そこからGPT-2(2020年)、GPT-3(2021年)と1年のスパンで最新バージョンが発表されていました。GPT-3が発表された2年後にGPT-3.5(2022)が発表され、その翌年にGPT-4が発表された流れになります。バージョンが上がるごとに着実かつ劇的に進化しており、少し前までは認知度もそこまで高くなかったのですが、現在では最新技術として大注目されるまでに実用的になっています。
進化の中での着目点
2018年の発表から劇的な進化をしきたGPTですが、モデルの仕組み自体は大きく変わっておらず、先ほど出てきた「Transformer」というモデルを使用しています。そのモデルのパラメータ数に関して、モデルの中にはいろいろパラメータを含んでいるのですが、その数はどんどん増えており、直近のところだとGPT-3では1750億パラメーターほどあるといわれていました。GPT-4は公表されていませんが、おそらく兆単位のパラメータを持っているだろうと予想されています。モデルの構造自体は一緒ですが、パラメータの数という意味では、非常に進化しています。
Transformer(トランスフォーマー)とは?
Transformerは「Attention Is All You Need」という論文(参考文献[1])で2017年にGoogleから発表されたモデルです。
計算効率の高さ
このTransformerの特徴ですが、これまでは再帰的(さいきてき)ニュートラルネットワーク(ReccurentNeuralNetwork:RNN)という自然言語処理が主流でした。ただこのRNNの特徴としては、一つの単語を処理して次の単語に進むという形態で、いわゆる直列処理になります。並列処理のように入力した文章を一気に計算するということができず、一つひとつ手前から処理していく必要があったので、並列処理ができる計算資源があったとしてもフル活用できないところがネックだといわれていました。そんな中で、この論文ではアテンションメカニズム(注意機構)という「文章中のどこに注意を向けると良いか」を学習する仕組みを利用したところ、入力中のすべての単語を同時に処理できるようになったということが非常に画期的でした。そうすることで、並列処理がフルに活用できるようになり、計算効率がとても高くなったところがエポックメイキングで時代を変えるものでした。
柔軟性の高さ
アテンションメカニズムを使うことによって、文章における単語間の関連性についてどこが重要なのか否か、といった部分をモデル自身が学習できるようになり、非常に柔軟性が高いという特徴を持てるようになりました。このGoogleの論文が出た直後から、これはすごいポテンシャルを秘めているのではないか、Transformerをどんどん学習させていけばすごいものができるのではないか、という噂が業界内ではずっと囁かれていました。その後GPT-1が発表され、着実に進化し、GPT-4というマルチモーダル化した優れたOpenAIができたという経緯になります。
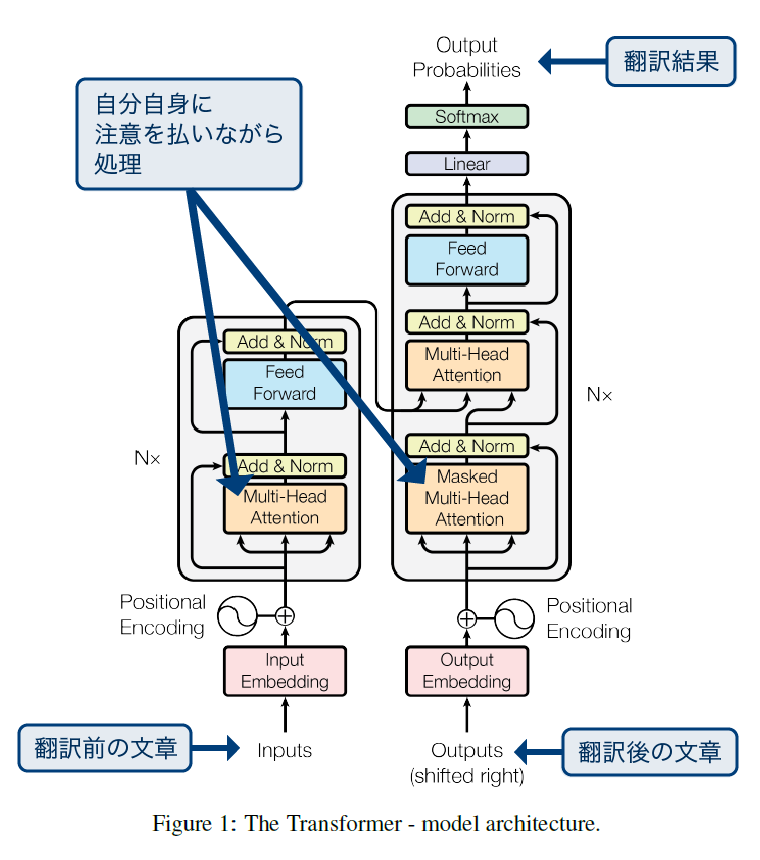
構造について
上記の図を参考に、左側がエンコーダー、右側がデコーダーと呼ばれる部分です。翻訳前の文章がデコーダーに入り、矢印を入れてる部分がアテンションメカニズムのブロックとして、自分自身に注意を払いながら処理する部分です。その後エンコーダーの方はこの翻訳前の文章をインプットして、文章の埋め込みベクトルというものを作成します。この埋め込みベクトルとは、文章の“どこが重要”かということや“各単語がどのように関連しているのか”といった情報を計算して作成されているものです。この埋め込みベクトルはデコーダーに後から入力する用途になっています。デコーダーの方はこの翻訳後の文章の単語列を入力し、同じようにアテンションメカニズムを経由して、その後デコーダーが作った埋め込みベクトルと合体させた後にアテンションメカニズムで計算した上で最終的な翻訳結果を出す、という構造になっています。
上記の図は非常に複雑なように見えますが、同じ動きをするプログラムを自分で動かすことは、頑張れば個人レベルで可能なレベルのロジック量です。
事前学習とは?

事前学習とは、大規模なデータセットを使用して事前にモデルに文書の情報を学習させることを指します。与えられた文章に対して単語を次々に予測し、実際の単語と比較することで文章の仕組みを学習するところが事前学習になります。
事前学習の特徴
教師なし学習として行われていることが一番の特徴です。教師あり学習の場合だと「太陽」という入力データに対し、翻訳結果として「SUN」というラベルデータを学習させる必要があり、そのデータを人が一つひとつ作ることになるので、膨大な時間がかかり現実的ではありません。しかし教師なしデータとして入れることが可能な場合、大規模なデータセットを学習させることが容易になるため、非常に効率が良くなります。
教師なし学習は教師がいなくてもデータの中のパターンや構造を自動的に学習するという点が最大の特徴になります。
使用するデータセット
大規模なテキストコーパス(GPTの場合、Wikipediaや書籍コーパスなど)を使用します。
効用
事前学習されたモデルは、言語の統計的な特徴や文脈を把握することができます。
ChatGPTのまとめ
- ChatGPTの「GPT」とは何か一言でいうとAIの「モデル」の一つ
- 柔軟性の高いTransformerの仕組みと大量のデータで事前学習することでできた優秀な言語モデル
- 現在(2023年7月5日時点)GPTの最新バージョンはGPT-4
- 教師なし学習は教師がいなくてもデータの中のパターンや構造を自動的に学習する
ファインチューニング(事前学習した後のモデルに、ラベルを予測するように学習/調整すること)を行わずに、 大量の事前学習だけで、さまざまなタスクを解くことができる汎用的なモデルを目指している。







